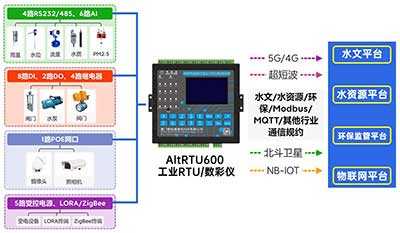
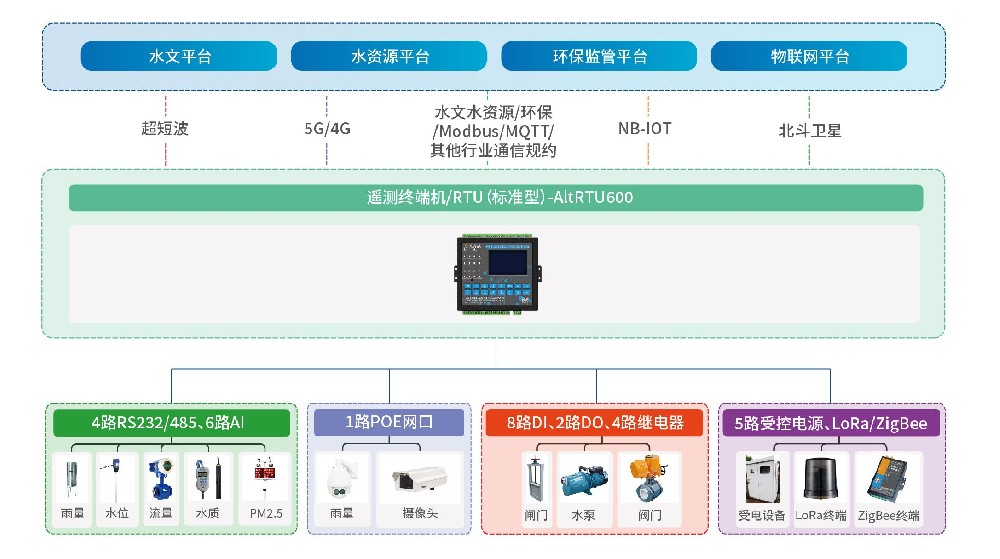
一�����、分布式DTU定義
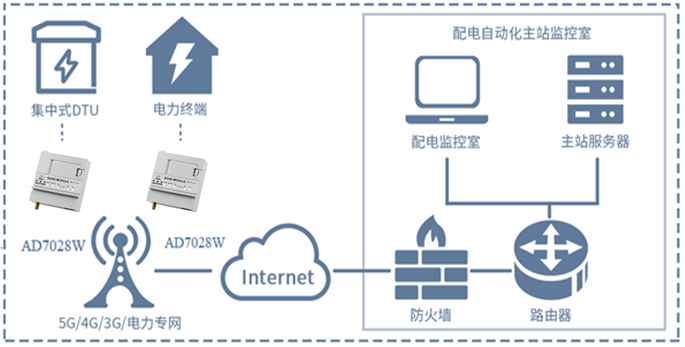
分布式DTU是一種創(chuàng)新的數(shù)據(jù)處理技術(shù)�,其核心在于將原本集中處理的數(shù)據(jù)任務(wù)分散到多個(gè)獨(dú)立的節(jié)點(diǎn)(通常是高性能計(jì)算機(jī)或服務(wù)器)上執(zhí)行�����。這種分布式架構(gòu)不僅能夠有效應(yīng)對海量數(shù)據(jù)的處理挑戰(zhàn)��,還極大地提升了系統(tǒng)的靈活性和擴(kuò)展能力�。每個(gè)節(jié)點(diǎn)作為數(shù)據(jù)處理的一個(gè)單元,既獨(dú)立工作又相互協(xié)作�,共同完成復(fù)雜的數(shù)據(jù)處理任務(wù)。
二��、分布式DTU的四大優(yōu)勢
1. 可擴(kuò)展性: 面對不斷增長的數(shù)據(jù)量�����,分布式DTU展現(xiàn)出了強(qiáng)大的適應(yīng)能力����。通過簡單地增加節(jié)點(diǎn)數(shù)量�,系統(tǒng)可以輕松擴(kuò)展處理能力����,確保無論數(shù)據(jù)量多么龐大,都能得到及時(shí)有效的處理�。這種靈活的擴(kuò)展機(jī)制,為企業(yè)應(yīng)對未來數(shù)據(jù)增長提供了堅(jiān)實(shí)的保障��。
2. 高效率: 分布式DTU采用并行處理策略����,將任務(wù)分割成多個(gè)子任務(wù),并在多個(gè)節(jié)點(diǎn)上同時(shí)執(zhí)行���。這種“分而治之”的方法顯著提高了數(shù)據(jù)處理速度���,特別是在處理大規(guī)模數(shù)據(jù)集時(shí),其效率優(yōu)勢尤為明顯�����。對于時(shí)間敏感型應(yīng)用����,如實(shí)時(shí)數(shù)據(jù)分析��,分布式DTU無疑是最佳選擇��。
3. 可靠性: 分布式系統(tǒng)的核心優(yōu)勢之一在于其冗余設(shè)計(jì)�����。在分布式DTU架構(gòu)中�,每個(gè)節(jié)點(diǎn)都承擔(dān)著一部分?jǐn)?shù)據(jù)處理任務(wù)�����,且節(jié)點(diǎn)之間通常存在數(shù)據(jù)備份或任務(wù)復(fù)制機(jī)制�����。因此��,即使某個(gè)節(jié)點(diǎn)發(fā)生故障����,其他節(jié)點(diǎn)也能迅速接管其任務(wù)����,確保數(shù)據(jù)處理過程不受影響��,從而大大提高了系統(tǒng)的可靠性和穩(wěn)定性�。
4. 廣泛的應(yīng)用性: 分布式DTU不僅適用于數(shù)據(jù)分析����、數(shù)據(jù)挖掘等傳統(tǒng)數(shù)據(jù)處理領(lǐng)域,還能很好地支持機(jī)器學(xué)習(xí)���、人工智能等新興技術(shù)的數(shù)據(jù)處理需求��。其強(qiáng)大的通用性和靈活性��,使得它能夠在金融����、醫(yī)療��、物聯(lián)網(wǎng)����、智能制造等多個(gè)行業(yè)發(fā)揮重要作用。
三���、分布式DTU的典型應(yīng)用場景
1. 大數(shù)據(jù)處理: 在大數(shù)據(jù)時(shí)代����,單個(gè)節(jié)點(diǎn)處理海量數(shù)據(jù)的能力有限。分布式DTU通過構(gòu)建龐大的計(jì)算網(wǎng)絡(luò)��,輕松應(yīng)對PB級甚至EB級數(shù)據(jù)的處理需求��,為大數(shù)據(jù)分析提供了強(qiáng)大的技術(shù)支持����。
2. 計(jì)算密集型任務(wù): 對于需要大規(guī)模計(jì)算資源的任務(wù),如基因測序��、天氣預(yù)報(bào)�����、復(fù)雜模型模擬等��,分布式DTU通過并行計(jì)算��,將計(jì)算任務(wù)分散到多個(gè)節(jié)點(diǎn)上執(zhí)行����,顯著縮短了計(jì)算周期,提高了計(jì)算效率�����。
3. 高可用性需求: 在金融交易��、在線服務(wù)���、關(guān)鍵基礎(chǔ)設(shè)施監(jiān)控等場景中���,系統(tǒng)的連續(xù)運(yùn)行至關(guān)重要。分布式DTU通過冗余設(shè)計(jì)和故障切換機(jī)制�,確保了即使在最惡劣的條件下,也能提供不間斷的服務(wù)�,滿足了高可用性需求。
4. 分布式存儲配合: 隨著分布式存儲技術(shù)的普及��,如Hadoop HDFS���、Ceph等����,分布式DTU與這些存儲系統(tǒng)的結(jié)合�����,實(shí)現(xiàn)了數(shù)據(jù)的分布式存儲與分布式處理的完美融合,進(jìn)一步提升了數(shù)據(jù)處理的整體效能�。
四、分布式DTU的數(shù)據(jù)處理流程
1. 數(shù)據(jù)采集: 這是數(shù)據(jù)處理的起點(diǎn)����,通過部署在現(xiàn)場的傳感器、物聯(lián)網(wǎng)設(shè)備等���,實(shí)時(shí)或定期采集各類數(shù)據(jù)���,并將其暫存于本地存儲設(shè)備中。
2. 數(shù)據(jù)聚合: 采集到的原始數(shù)據(jù)往往雜亂無章���,需要進(jìn)行預(yù)處理��。數(shù)據(jù)聚合階段,系統(tǒng)會對數(shù)據(jù)進(jìn)行清洗����、格式化、分組等操作�����,為后續(xù)處理奠定基礎(chǔ)。
3. 數(shù)據(jù)傳輸: 經(jīng)過聚合的數(shù)據(jù)�,通過高速網(wǎng)絡(luò)或?qū)S猛ㄐ沤橘|(zhì),安全��、高效地傳輸?shù)椒植际较到y(tǒng)中的各個(gè)目標(biāo)節(jié)點(diǎn)�。這一過程要求數(shù)據(jù)傳輸協(xié)議的高效性和安全性。
4. 數(shù)據(jù)處理: 目標(biāo)節(jié)點(diǎn)接收到數(shù)據(jù)后�����,根據(jù)具體任務(wù)需求�����,進(jìn)行計(jì)算���、存儲����、轉(zhuǎn)換等操作���。這一階段是分布式DTU發(fā)揮并行處理優(yōu)勢的關(guān)鍵�����。
5. 數(shù)據(jù)分析: 最后����,利用先進(jìn)的數(shù)據(jù)分析工具,如Python����、R語言、Spark等����,對處理后的數(shù)據(jù)進(jìn)行深度挖掘和分析,提取有價(jià)值的信息和洞察�����,為決策支持提供依據(jù)�。
無線路由器|全網(wǎng)通網(wǎng)關(guān)|DTU|RTU|數(shù)采儀|遙測終端機(jī)|嵌入式網(wǎng)關(guān)|云平臺開發(fā)-廈門愛陸通")